Understand the Terms¶
Mining is perhaps the most confusing metaphor within all of Bitcoin. It can be better understood as transaction processing, allowing for final international settlement -- as well as for issuance, ensuring that the supply schedule stays on its predetermined course. Unfortunately, there's no one word to adequately describe all of that, hence the circumlocutions necessary to describe what Bitcoin "mining" really is.
For these reasons, we've called this section Proof of Work. Because for better or worse, the entirety of Bitcoin mining, international settlement processing, whatever you want to call it -- all rests on top of what is known as a proof of work consensus mechanism.
We will attempt to demystify proof of work and provide a clear and technically accurate understanding of how mining works.
Hashing¶
Despite how often it is said, Bitcoin mining is not concerned with solving complex math problems. Bitcoin mining is just hashing. The "proof" in proof of work is simply a hash that proves a certain amount of hashing (that is, work) was done. The important part is not the math function, the important part is the proof of work.
what is a hash?
A "hash" refers to the output of a hash function, which is a math function that takes input of any size and maps it to a fixed-sized output. A good hash function should be deterministic, with uniformly distributed output, and be non-reversable (that is, you cannot determine what the input was if you only have the output).
A hash function can certainly be considered a "complex math function" (not exactly a "math problem"), but that is decidedly not the point of Bitcoin hashing -- the point is proof of work.
The output set of a hash function (that is, the set of all possible outputs) can be small (useful for data indexing) or extremely large (useful for cryptography). Bitcoin mining uses SHA-256.
SHA-256¶
SHA-256 is a hash function that maps any input into a number somewhere between 0 and 2256. This set of numbers is so large it's on the scale of atoms in the universe. It's so astronomically large that the chance two human-generated inputs mapping to the same output (what would be known as a collision) is considered so infeasible as to be impossible. And in fact there are exactly zero known collisions in SHA-256 and finding a collision would likely take beyond the heat death of the universe to discover.
That said, what if instead of a collision, you just wanted to find an input whose SHA-256 output was smaller than a target number? If it's a very large target number, say 2255 then this would be trivial (50% of all inputs would produce a hashed output smaller than that, basically a coin toss). But if it was a very small target number, then it would be extremely difficult to find any input that produced a hashed output that was smaller.
For example
Let's look at some example SHA-256 outputs,
1 => 6B86B273FF34FCE19D6B804EFF5A3F5747ADA4EAA22F1D49C01E52DDB7875B4B
2 => D4735E3A265E16EEE03F59718B9B5D03019C07D8B6C51F90DA3A666EEC13AB35
3 => 4E07408562BEDB8B60CE05C1DECFE3AD16B72230967DE01F640B7E4729B49FCE
three => 8B5B9DB0C13DB24256C829AA364AA90C6D2EBA318B9232A4AB9313B954D3555F
Three => 926F52D1C1E19C0C58A7D39BF234A0D239352F5ACFA26C73989D9C3845614999
Three? => F9DCE11BE6E27EA81231A766A4210EAA05D51E4C5F5F79C8FD0133274201D543
Each output is a hexadecimal representation of a number (that is, a very large base-16 number). Notice that small changes in the input produce radically different outputs. In fact, there's no way to predict where in the 2256 output set a given input will land (other than to perform the SHA-256). And as expected, exactly 50% of those outputs are less than 2255.
Also notice that none of these output numbers are particularly small. For comparison, let's look at the SHA-256 output of the Bitcoin genesis block,
00000000839a8e6886ab5951d76f411475428afc90947ee320161bbf18eb6048
Notice the leading zeros. This number is clearly much smaller than the previous SHA-256 outputs. In this case the target was
00000000FFFF0000000000000000000000000000000000000000000000000000
And indeed the SHA-256 output of the genesis block is smaller than this target.
Compare this to a more recent block hash, block 772244,
000000000000000000032c4341255c7b108f3982b71b6e734d25b89bb9b1cc41
By looking at the leading zeros it is obvious that this number is considerably smaller than the genesis block (and thus more work was required to find an input that produced such a small SHA-256 output). In fact, the probability of guessing an input with a SHA-256 output that small is so small that you're more likely to be struck by lightning every day of the week at noon.
This simple observation is the basis of Bitcoin mining. Importantly, finding input whose SHA-256 hash output is smaller than a target can only be done through a brute force search; and thus the very existence of such an input would prove a certain amount of brute force work was done.
Other hash functions
In addition to SHA-256, Bitcoin makes use of other hash functions; in particular RIPEMD-160, used in conjunction with SHA-256 to generate Bitcoin addresses.
However, within Bitcoin mining proof of work, it is entirely a game of SHA-256 hashing.
Hashrate¶
As the name implies, hashrate is simply the number of SHA-256 hashes per-second happening in order to successful discover a new block. There are great real-time visualizations of hashrate over time. Hashrate across the entire Bitcoin network is estimated based on the time between blocks and the current network difficulty. In general, the faster you are producing valid blocks for a given difficulty, the more hashrate you have.
Importantly, hashrate is the measure of total work being done. From a protocol perspective, we only care about hashrate, and not the physical energy consumed by the miners to produce that hashrate. Energy usage (e.g, in Watts or Joules-per-Terahash-second) is entirely dependent on the mining devices themselves. And this simple inflection point of Watts to Hashrate is where the realm of abstract mathematics unites with our physical world. This is ultimately why Bitcoin has value, because producing Bitcoin takes real energy in the real world (measured in Watts), and it does so through a fixed and known supply schedule.
ASICs¶
Application-Specific Integrated Circuit or ASIC is nothing new, and in Bitcoin mining this refers to a specific chip that calculates SHA-256 hashes (and nothing else). However, an "ASIC" can also refer to the mining device itself (which has hundreds of ASIC chips).
Initially, Bitcoin mining happened on CPUs, and then GPUs. And due to economic incentives mining moved to FPGA chips and then eventually to modern ASICs. At every step of this evolution the incentives are pointing to the maximum amount of hashrate for the minimum amount of electricity consumption.
It is difficult to know what the next evolution of Bitcoin mining technology will be. It might be quantum ASICs powered by clean nuclear energy. It might be highly decentralized commodity ASICs producing hash from geothermal energy. Whether it be advances in quantum computing, or advances in energy production, Bitcoin mining will be incentivizing much needed innovation.
Difficulty¶
Difficulty is the measure of how difficult it is to find a valid block. Every 2016 blocks the difficulty will be adjusted to match a 10-minute average time between blocks. In other words, if blocks are coming in faster than every 10-minutes, the difficulty will increase; if blocks are coming in slower, the difficulty will decrease.
The formula for difficulty is based on the target number discussed above. Specifically,
difficulty = difficulty_1 / target
And difficulty_1 is the highest possible target allowable in Bitcoin
(in other words the lowest allowable difficulty),
difficulty_1 = 00000000FFFF0000000000000000000000000000000000000000000000000000
Note that as difficulty increases the target number decreases (that is, it becomes more difficulty to find a SHA-256 hash less than the target).
Network Difficulty¶
Network difficulty refers to the difficulty across the entire Bitcoin network. That is, the difficulty needed to find a valid block. When Bitcoin was first released in 2009 the network difficulty was 1.0, and this number slowly increased as more participants joined and started mining. By 2012 the difficulty was over a million (that is, over a million times more difficulty).
In the age of ASICs, the network difficulty has grown astronomically large, and continues to grow. For example, block 772244 (mentioned above) has a difficulty of 37,590,453,655,497.09 (over 37-trillion). This corresponds to a hashrate of over 250 exahash -- that is, over 250-quintillion SHA-256 hashes per-second.
To put this into perspective, if we attempted to log all of the quintillions of hashes per-second then we would exhaust all know storage space (all cloud storage, all personal computers, all mobile devices) in only a few seconds. Bitcoin's global hashrate is now so large it has outgrown our current (and otherwise impressive) global data storage capacity.
Session Difficulty¶
Typically, session difficulty refers to the specific difficulty assigned to a miner. While the network difficulty is used to find a valid block, the session difficulty is a way to find valid shares that act as a proof of work for an individual miner (or a pool of miners). For example, a modern ASIC might use a session difficulty of 65,536 and generate valid shares every few seconds.
A share is simply a block that meets the session difficulty (but not necessarily the network difficulty). These shares are themselves a proof of work, specifically it is proof that a given miner did work.
Share Difficulty¶
A valid share must meet the session difficulty, which just means its SHA-256 hash is smaller than the target computed from the session difficulty. In other words, every share will have its own difficulty which is greater than the session difficulty. And if the share difficulty is greater than the network difficulty then that share is a block!
Luck¶
Luck is a measure of -- you guessed it -- luck. Specifically, the luck of finding a valid block in a given period of time. It's similar to the probability of finding a block given a specific amount of hashrate. Technically, luck is simply the following formula given shares between two blocks,
sum(session_difficulty) / network_difficulty
In other words, if luck is 1.0 (100%) then you mined a block when your own proof of work was equal to the current network difficulty. If your luck measure was greater than 1.0 then this is bad luck (meaning you did more work for that one block than implied by the current network difficulty). And if your luck was less than 1.0 then this is good luck (meaning you found a block before doing all the work implied by the network difficulty). In practice, the luck between any two blocks will vary, sometimes good and sometimes bad luck. However, the average luck over time should convergence on 100% (by definition).
Over a period of N blocks, luck is simply,
sum(session_difficulty) / (N * network_difficulty)
In a perfectly efficient and error-free system, luck will converge on 100% as N gets larger. And if luck is greater than 1, even by a small fraction, say, 1.02 (102%), then that denotes bad luck -- meaning you didn't mine as many blocks as you should have for the hashrate you produced. Imagine you did the work for 102 blocks but were rewarded 100 blocks. This might just be legitimate bad luck. But over time, let's say you earned 1,000 blocks with a luck of 102%, meaning you missed 20 blocks -- this is persistent bad luck, and is not statistically feasible, and thus is a sign something is wrong with your miners (block withholding, rejected orphaned blocks, compromised firmware, etc).
Blocks¶
Ultimately, the entire goal of Bitcoin mining is to find and propagate blocks. Finding a block means finding a valid block whose SHA-256 hash is less than the current network difficulty target. More specifically, the hash of the block headers must meet this difficulty, and the block itself must be valid (otherwise the nodes in the Bitcoin network will reject this block).
Block headers¶
A block header is composed of a small number of fields that when input into a SHA-256 will produce a hash that is less than the target (computed from the network difficulty).
version-- a 4-byte field used to track version, and (since BIP-9) is used to signal for soft forks (backwards compatible upgrades to the protocol)timestamp-- a 4-byte field containing the Unix timestamp; must be greater than the average of the previous 11-blocks and less than 2-hours past the current network-adjusted timestampdifficulty-- a 4-byte compressed representation of the current network difficultynonce-- number used only once, a 4-byte number used by miners in order to test different hashesprevious block hash-- a 32-byte field holding the SHA-256 of the previous block -- this ensures that no previous transaction was modifiedmerkle root-- a 32-byte field holding the Merkle tree of all transactions in the block
When mining Bitcoin, the nonce
is directly modifiable to work on.
However, modern ASICs will exhaust
the 4-bytes of nonce instantly.
Miners could potentially
use the variance in the timestamp,
artificially adjusting the timestamp
such that it's still
valid (according to the consensus rules).
But in practice nonce and a handful
of bits of timestamp do not give
sufficient search space for modern
ASIC miners (with all their hashing power)
-- instead,
modern ASIC miners modify the transactions,
typically the coinbase (the very first
transaction in a block),
adding extranonce fields.
Because this will modify transactions this
will require a new
merkle root for every variation.
The merkle root is a Bitcoin-specific
Merkle Tree
which is effectively a SHA-256 hash of hashes
of all the transactions in a given block.
The purpose of a Merkle Root is to prove
that a given set of transactions produces
a given SHA-256 hash
(a way to validate that the transactions
in a given block were not modified).
Block height and weight¶
Every block has a valid proof of work hash, and is also indexed by its block height. Block height is simply the number of blocks prior to any given block, and is an easy way to reference a given block. E.g., block height 772,615 has exactly 772,615 blocks prior to it.
If you look at the details of a given block, e.g., block 772,615 you will see that it also has a block weight, in this case, 3.99 MWU. The block weight is simply the size of a block, measured in weight units where MWU is million weight units.
Block propagation¶
Once a miner finds a new block it needs to propagate that block to the rest of the network. Typically, this is done through the submitblock RPC command in Bitcoin Core. Failure to propagate quick enough can result in an orphan or stale block, which means the miner gets zero reward despite their proof of work.
Once a miner submits a new block, the p2p network of Bitcoin nodes will propagate the new block (each node verifying the proof of work and validity). Historically, this process was somewhat slow. However, since BIP-152 the nodes propagate blocks using a compact message format that only includes block headers and a compact list of transaction IDs. Because each full node manages its own mempool, it already has most of the transactions, so it's able to assemble the block quickly (only fetching transactions that it doesn't already know about).
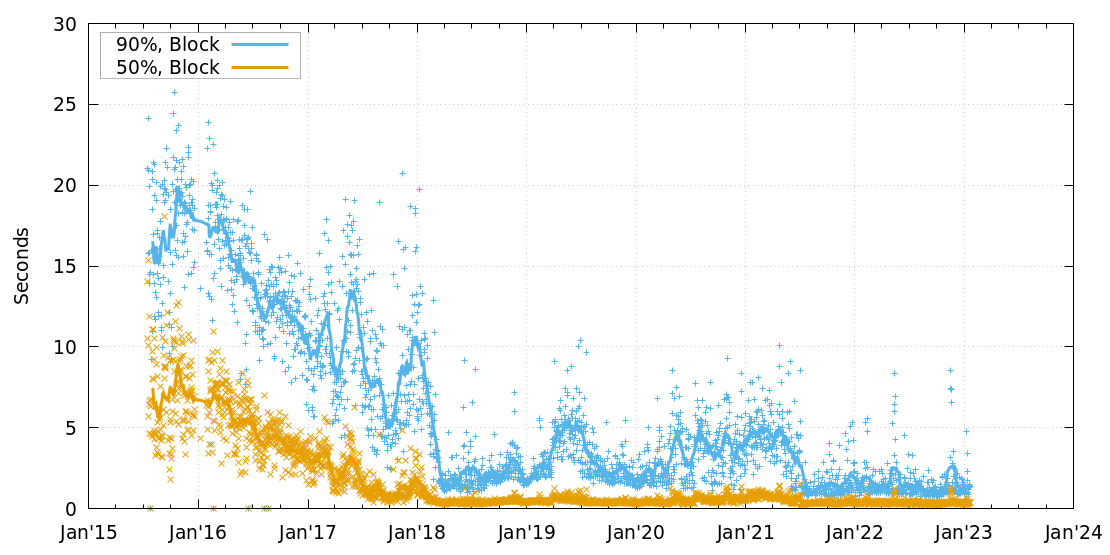
Compact block messages led to a signifant reduction in block propagation time, which in turn greatly reduces the risk of oprhaned blocks.
Pools¶
Mining is all about probability. If you're a large miner with 10% of the total hashrate, then you will be expected to mine 10% of the total number of blocks. There are on average 144 blocks per day, so 10% is 14.4 blocks per day. A miner with 1% would average 1.4 blocks per day, and so on.
But what about small miners? What about an individual mining device?
Let's look at block 772,793. This block was mined through Solo CK purportedly by an individual miner with only 10 terahash. 10 terahash out of 284 exahash (at the time). That's 10 / 284,000,000. This means they will mine 0.0000003% of all blocks, and statistically should take about 540 years before finding a block.
This rare luck aside, most individual mining devices will never find a block, ever. A mining device might have an operational life of 10 years, probably less, which is far less than the centuries it would take to find a block. Blocks are finite, 144 per day, 52-thousand per year. And there are millions of miners, all competing against the ever increasing network difficulty.
This was a problem even early in Bitcoin's history. As a result, in 2010, pooled mining was born. The idea is simple, pool your hashrate and share the reward based on contributed hashrate. A small miner doesn't have to wait 540 years or be extremely lucky -- they can get paid a small amount daily.
Miners in a pool use the pool's coinbase address, and expect payout from the pool (as their shares prove they did work for the pool). There are different payout strategies where risk is either shared amongst pool participants, or the risk is owned entirely by the pool itself. Additionally, work is coordinated across all the participants of a pool through a protocol known as stratum.
Stratum¶
For better or worse, stratum is the defacto protocol for pools to manage workers. It is a raw-socket protocol using newline-delimited JSON (rather than websockets or any other standard). And while stratum v2 promises to solve many of the problems with stratum, until there's wide adoption of v2 in mining firmware, stratum will remain the standard.
Importantly, modern firmware lacks the ability to call getblocktemplate on a full node, and simply requires a stratum url in order to function. There is no technical reason for this, but a consequence of market demand for fleets of ASICs and pooled mining. If you have a modern ASIC, you will need a stratum server (from a pool or otherwise) to start mining.
Pay-per-Share¶
This is the most common payout strategy for pools, and is typically full-pay-per-share (FPPS). You may see PPS or PPS+ as slight variations of this strategy. Simply put, the risk is on the pool itself and not the miners. The miners get paid for their shares regardless of whether the pool is propagating blocks. In fact, the risk of orphans or any operational inefficiency is owned by the pool (even if there's a problem with one of the miners).
An FPPS pool will set a session-difficulty and an FPPS rate, and a miner gets paid for all shares above that difficulty. If a share happens to be a block, the miner gets paid for just another share. If the miner withholds a block (intentionally or accidentally), the miner loses only a negligible amount of payout, and the pool loses an entire block.
While this strategy has proven very popular in recent years, it is unlikely to survive as a viable business model -- and in fact most FPPS pools offer other services to offset their (predictable) losses.
Pay-per-Last-N-Shares¶
This is an alternative pool strategy, abbreviated as PPLNS with variations like SPLNS. In this payout strategy, risk is shared amongst all miners in the pool. The miners get paid when the pool mines a block, and the payout is based on their recent shares.
If there is block withholding (intentional or otherwise) every miner in the pool suffers, finding that their luck measure becomes persistently bad. For this reason, most miners prefer FPPS pools, especially if they can negotiate a low (or no) FPPS fee.
Solo¶
Because of the requirement for stratum servers and the complexity of block propagation, some pools offer a solo mode. In this strategy, risk is owned entirely by each miner, they either mine blocks or they don't. The pool operator is paid a fee for providing a stratum service alongside well-peered full nodes for block propagation.
Importantly, if a miner is using a pool for solo mining, they are entirely dependent on that pool for efficient worker management (that is, coordinating work amongst a fleet of miners), as well as for propagating blocks. And because the miner owns all of the risk, using a pool for solo mining is only viable for those that lack the engineering resources to manage stratum servers and full nodes. Otherwise, solo mining is best done, well, solo -- as in, run your own stratum server and full node.