ASICBoost¶
Are there any unrealized ASICBoost-like optimizations one could find in existing miners (perhaps in a solo-mining configuration not bound by stratum, such as with custom firmware)?
What is ASICBoost?¶
From the original whitepaper: “AsicBoost [sic] is a method to speed up Bitcoin mining by a factor of approximately 20%. The performance gain is achieved through a highlevel optimization of the Bitcoin mining algorithm which allows for drastic reduction in gate count on the mining chip.”
In simpler terms, ASICBoost is an optimization based on the insight that the 80-byte block-header is divided into two chunks when computing a SHA-256 hash (a Bitcoin block hash is a double SHA-256 of the 80-byte block-header). The SHA-256 hash function uses 64-byte chunks of the message to hash, and processes each chunk into an expander function, and finally into a compressor function to produce the final 32-byte (256-bit) output.
From a SHA-256 perspective, here is how a block-header will be chunked:
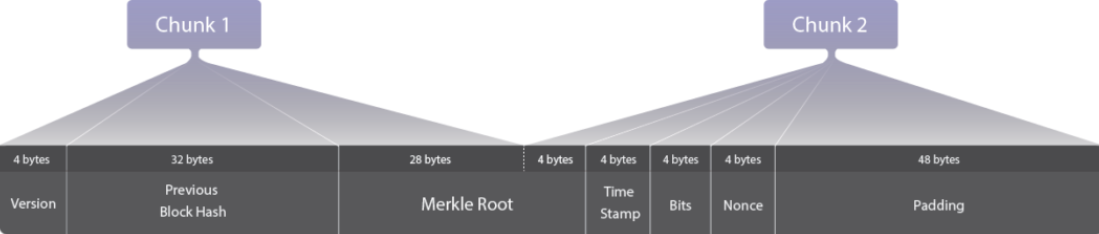
When iterating on the Nonce, nothing in Chunk 1 would change. Once the Nonce in Chunk 2 is exhausted, the extranonce field in the coinbase will increment, requiring a new Merkle Root and a new Chunk 1.
In pooled mining, there are multiple extranonce fields in the coinbase, typically:
- extranonce1 – a unique value between the stratum server and the miner; this will not change by the miner but is set by the pool itself (unique each miner)
- extranonce2 – an additional field (immediately after extranonce1) that is incremented by the miner when it exhausts the nonce space
A “traditional mining loop” follows this exact approach, an outer-loop that modifies Chunk 1, and an inner-loop that modifies Chunk 2. The “ASICBoost loop” flips this approach such that multiple Chunk 1 values can be used for each Nonce (each Chunk 2); effectively eliminating one of the expander functions that would be required in the traditional loops (see the research paper for details).
The goal is to find Chunk 1 “collisions” (that is, different values of Chunk 1 that do not effect the last 4-bytes of the Merkle Root, which is part of Chunk 2).
The theoretic performance improvement is up to 25% (removing one of the expander functions); and the more Chunk 1 collisions one can find the better the gains. From the original paper:

Overt ASICBoost¶
In practice, the most efficient (and simplest) way to take advantage of ASICBoost is to use the available bits within the Version field of the block-header. This method is known as “overt” because it’d be obvious that the Version bits were used (effectively this extra-nonce space, but done in Chunk 1 via an “ASICBoost loop”). And ever since BIP9, much of the Version header is available for use in mining.
Importantly, this can be done in software on GPUs and FPGAs, but for ASICs require a specific chip design, which modern ASICs have already implemented.
Covert ASICBoost¶
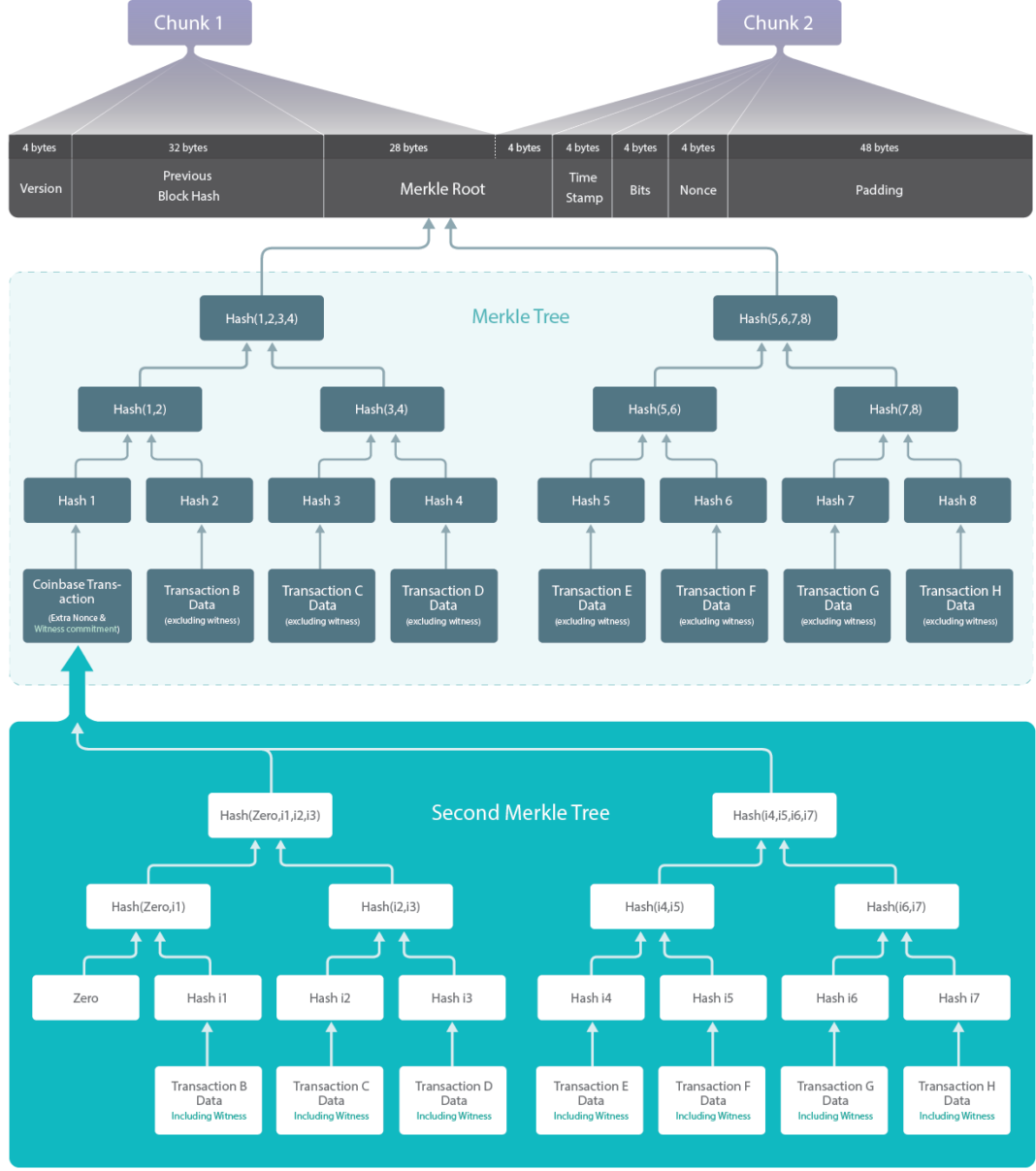
The only other part of the block-header from Chunk 1 that can be modified is the Merkle Root itself, and in order to find collisions one would need Merkle Roots that differed in the first 28-bytes but shared the last 4-bytes (which is part of Chunk 2). This method is known as “covert” because it’s nearly impossible to detect, because in practice it would be indistinguishable from normal Merkle tree rolling that one would see in the “traditional mining loop” (that is, changing the extranonce2).
It may seem difficult to find collisions, 4-bytes is 32-bits, thus 2^32 of brute force hashing, but due to the birthday paradox we can find collisions in sqrt(2^32). Thus within 65K brute force attempts we can find 4-byte collisions. In other words, we don’t need a specific 4-bytes, we just need as many 4-byte collisions as we can find.
Discovering Merkle Root collisions can be done by modifying the transactions, as well as by re-ordering transactions. Interestingly, this approach would be compute-heavy with larger blocks (as one re-computes the entire Merke tree for each potential collision), but would be very efficient in an empty block (where the Merkle tree is just the coinbase txn id).
While empty blocks are extremely rare in mainnet, they do happen (e.g., block 818960 from AntPool). These usually happen when a pool mines two consecutive blocks in a row; arguably because the pool’s stratum server is still waiting on a new block template. But it’s worth noting that Covert ASICBoost benefits from empty blocks in exactly this situation, as it will take longer to build new candidate block templates using Covert ASICBoost than in a traditional mining loop.
SegWit is incompatible with Covert ASICBoost¶
SegWit (segregated witness, see BIP141) presents challenges for Covert ASICBoost, ultimately adding computational difficulty to any block template with even a single SegWit transaction. This is because the coinbase transaction contains a second Merkle Root (similar to the Merkle Root in the header, but the second Merkle Root is based on the full transaction data, including witness data). In other words, finding a collision in Chunk 1 is effectively impossible to do in a computationally efficient way.
Why bother with Covert ASICBoost?¶
Obviously, Overt ASICBoost is vastly simpler and more efficient (also compatible with SegWit). There is no need to detect collisions, no preference for smaller blocks, but it would be difficult to hide. The only advantage to Covert ASICBoost is that it could give a competitive advantage to a pool who could activate it while other pools could not (an insider advantage).
As far-fetched as that sounds, this is exactly what bitmain (allegedly) did with AntPool, advertising a 20-30% hashrate improvement when certain bitmain miners were using AntPool. While they denied using Covert ASICBoost to gain a competitive advantage for AntPool, all evidence points to them doing this (such as increase hashrate, patents, increase in empty blocks, reluctance to support SegWit, etc). Oddly, bitmain denied the allegations while simultaneously admitting that they had developed exactly this capability. This was in the midst of the so-called Blocksize War, where tensions between miners and core developers were high.
After considerable complaints and outcry from the Bitcoin community, bitmain began offering Overt ASICBoost firmware, which has now become standard on all miners (not just bitmain).
SegWit and Overt ASICBoost Win in the End¶
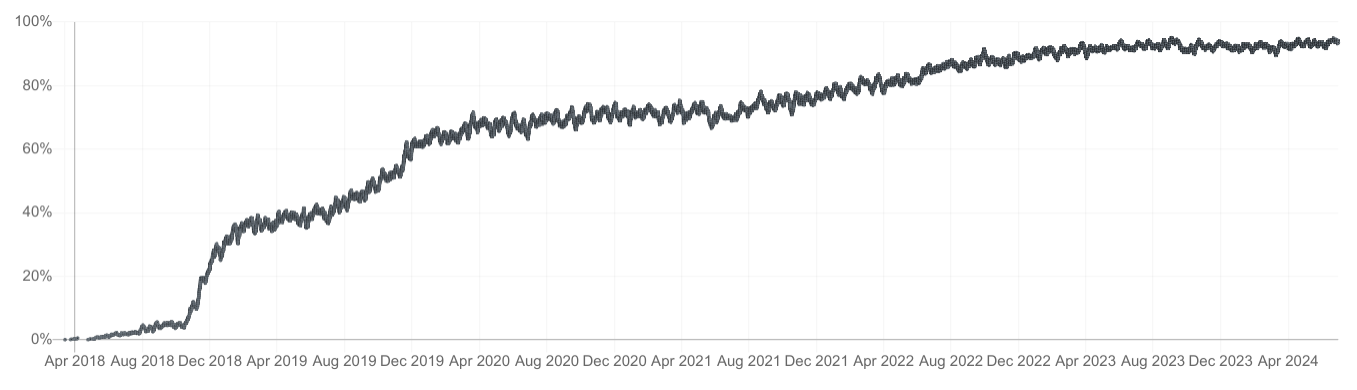
SegWit was activated in 2017 and saw significant adoption in the following years, and today accounts for almost all Bitcoin transactions. Not surprisingly, the adoption of Overt ASICBoost followed a very similar curve as SegWit, and now accounts for nearly 100% of Bitcoin hashrate.
Are there any unrealized ASICBoost-like opportunities?¶
Unfortunately, no.
While there might be unrealized ASICBoost-like improvements in the SHA-256 ASIC design that have never been discovered, there is no known benefit that has not already been realized by Overt ASICBoost. That is, even if one was solo-mining with custom firmware (and not bound by stratum nor stock firmware) there are no known optimizations that Overt ASICBoost is not already taking advantage of. The Version header offers ample room for realizing the benefit on the existing silicon, and even if additional Merkle Root collisions could benefit, the dominance of SegWit has completely closed that door (unless one wanted to filter out all SegWit transactions while mining, but this is a dead-end as block subsidies will continue to halve and fees will become the primary driver of hashrate).